
Split Hardware Transactions- support for True nesting of transactions
Even though the title says Hardware transactions, this is still a hybrid style TM paper that came after HTMs/STMs were relatively mature around 2008- PPoPP’08. This is a very different paper out of all the hybrid papers because it addresses something different- most hybrid papers try to address the HTM limitations of space (read-set/write-set size) by re-trying them as STMs but this paper tries to make closed nested TMs to be more open or what they call “True nesting.”
Purpose of the paper: to provide true nesting to closed nested TMs
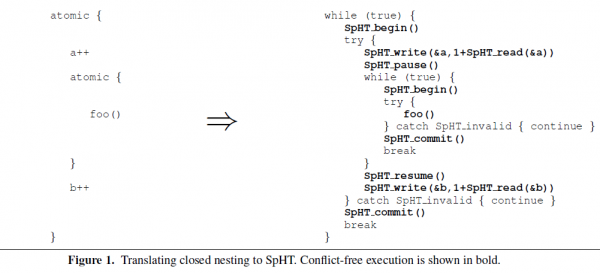
Closed nesting demands strong atomicity. The simplest implementation of closed nesting is to flatten each child transaction into its parent. This conservative approach is problematic- if any child conflicts with another transaction, the parent must be aborted and rolled back too. The paper instead tries to provide true closed nesting of transactions: when a nested transaction aborts, only the nested computation is retried if the computation in parent transaction up until now is conflict-free. This is important to support because:
- This obviously improves performance but reducing redundant work done on re-try.
- More important, true nesting is an important prerequisite for implementing desirable exception semantics. Throwing an exception inside a nested transaction, and catching it in the parent transaction, requires the use of true nesting- otherwise, you would always keep redoing the entire parent without may be forward progress.
- True nesting is necessary to support alternative atomicity: allowing the programmer to take an alternative action if a transaction aborts- eg: if we had an orElse construct inside a TM specifying a series of atomic blocks; each is attempted in turn until one succeeds. True nested execution of these alternatives is necessary, otherwise failure of the first alternative will cause failure of the parent and subsequent alternatives will never be attempted.
Proposed Solution:
The high level idea behind SpHT algorithm:
- An atomic block is executed using a split transaction, which is a transaction divided into multiple segments. Each segment of the split transaction is executed using a separate hardware transaction. (this HTM can be any HTM implementation- they don’t modify the inner implementation).
- Shared memory writes (LLC writes) in a segment are deferred, and are instead logged in a thread-local write set (a thread-level/application level software allocated write-set space in main memory- so essentially, you have a log for the outer-nesting of the TM till the end of last sub-segment). This allows us to commit the HTM write-set executing a segment at its commit point and still have the capability to rolling back to top of the nesting in case of conflict later. This provides isolation.
- Shared memory reads in a segment are logged as well, in a thread local read set. A hardware transaction executing one segment can validate the reads performed by previous segments by re-reading all the locations in the read set and verifying that the values in these locations are the same as those in the read set. This guarantees consistency.
- Finally, the last hardware transaction copies the written values from this thread local outer-TM’s entire write set to shared memory at its commit point. The linearization point [14] of the split transaction is the linearization point of this final hardware transaction.


Author’s evaluation of the solution:
They show that the implementation does better than STMs but not pure HTMs (which is expected) by they way they bridge the performance gap quickly as number of threads increase. This method scales well and has definite application in the niche problem they try to solve.